Overparameterization, Implicit Bias, and Double-Descent
Machine Learning Fundamentals for Economists
Classic Statistics: Single Descent

from https://arxiv.org/abs/1812.11118
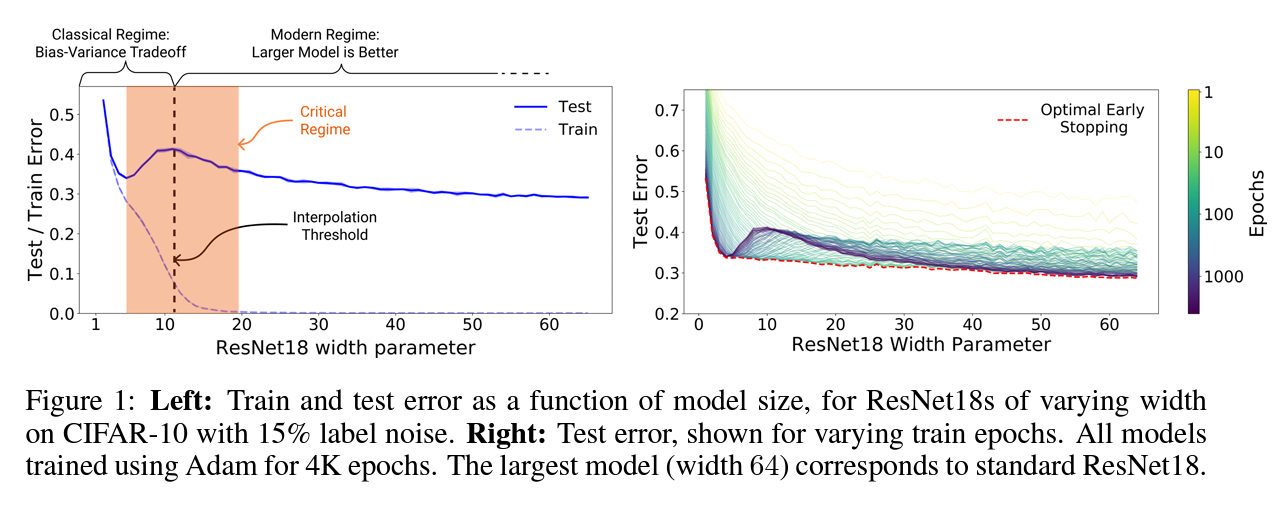
Double Descent

from https://arxiv.org/abs/1812.11118
Example Fitting Small Number of Data Points
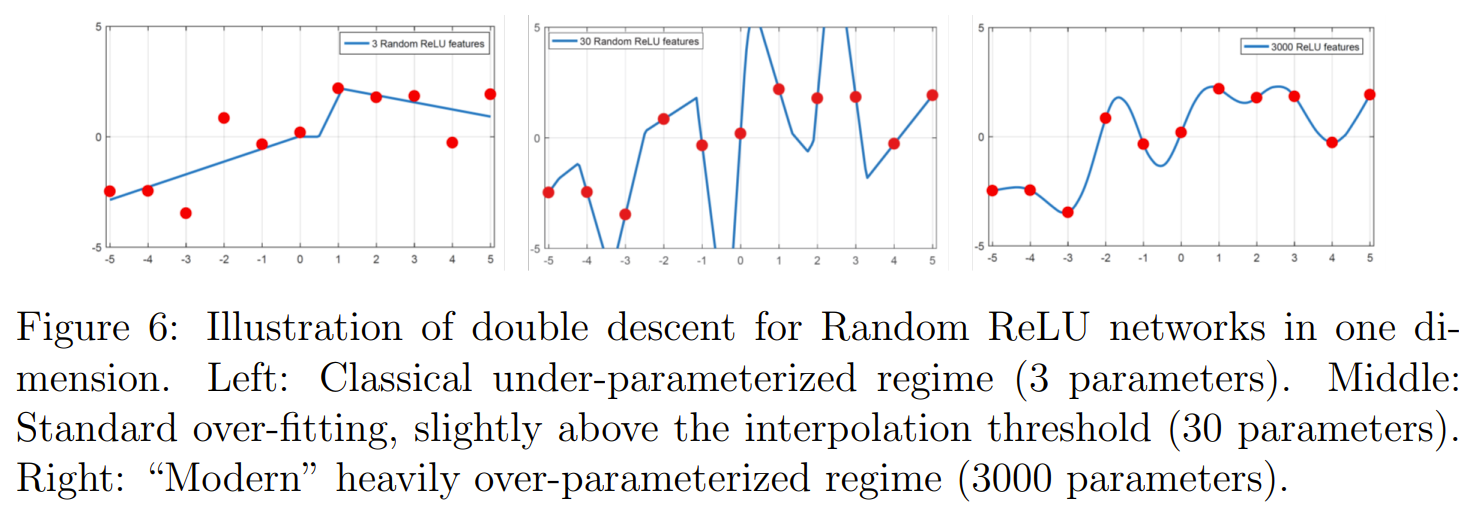
from https://arxiv.org/pdf/2105.14368.pdf
Example with Increasing “Width” of Neural Network
from https://arxiv.org/pdf/1912.02292.pdf
Overparameterized ERM Has Many Global Minima
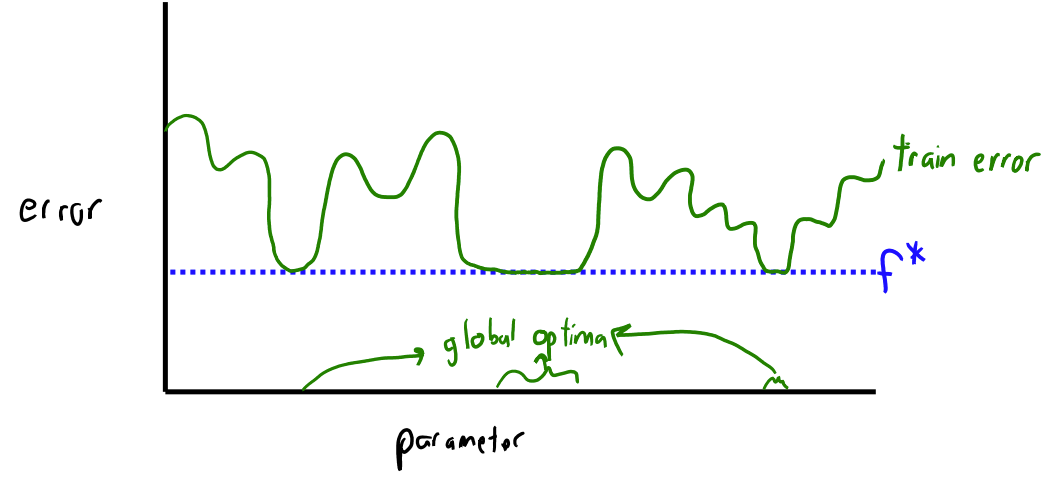
See https://www.cs.ubc.ca/~schmidtm/Courses/440-W22/L7.pdf
- With overparameterization, there are many global minima
- In high dimensions the global minima become increasingly connected
Not All Global Minima are Alike
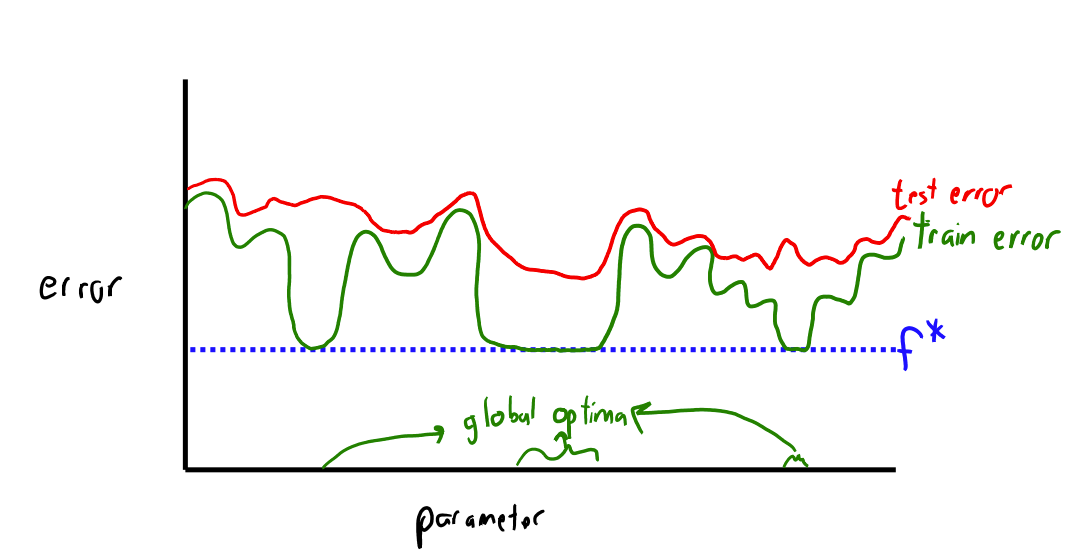
See https://www.cs.ubc.ca/~schmidtm/Courses/440-W22/L7.pdf
- Some parameters generalize (estimated with test error) better than others
- Intuition: better with more “volume” of parameters at low test error
Flat vs. Sharp Geometry
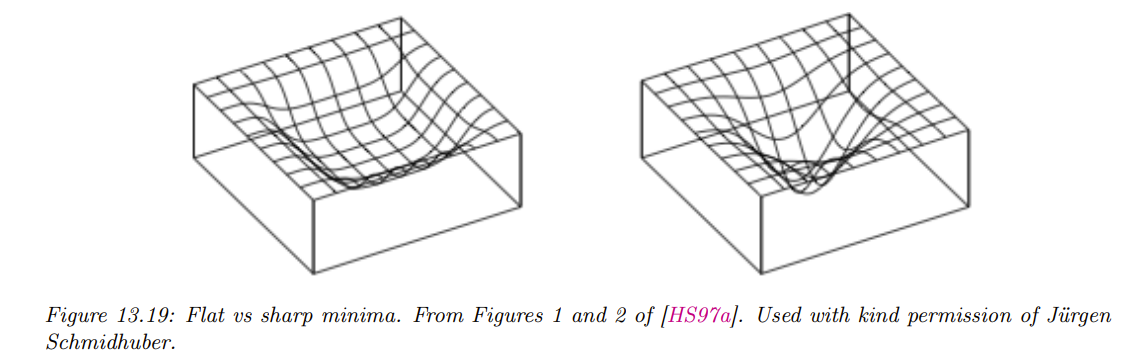
from ProbML Book 1 Section 13.5.6
- We often think of flatter geometry near minima as worse (e.g., not identified)
- With overparameterization this is the wrong intuition.
- Flat minima generalize better because they have similar loss over a larger volumes of parameter space. Less dependent on individual data
SGD Finds Flat Minima
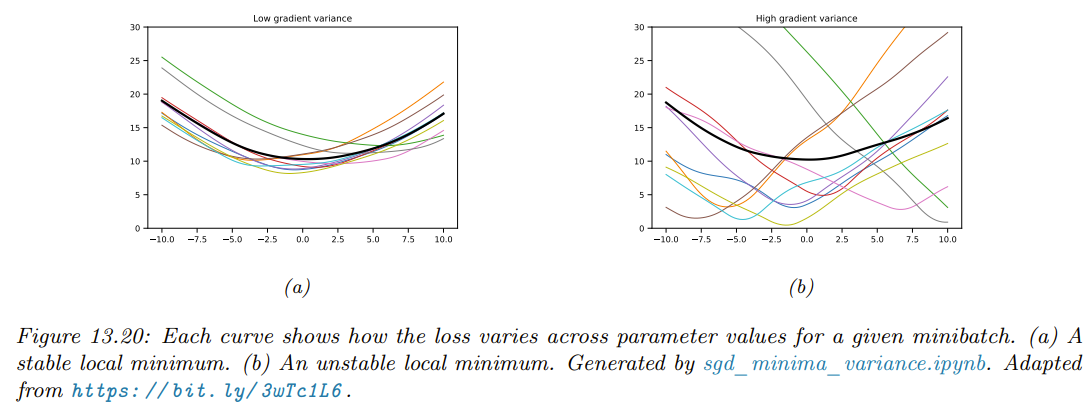
from ProbML Book 1 Section 13.5.6
- SGD finds more stable local minima, less sensitive to underlying data
Overparameterized Loss Landscapes
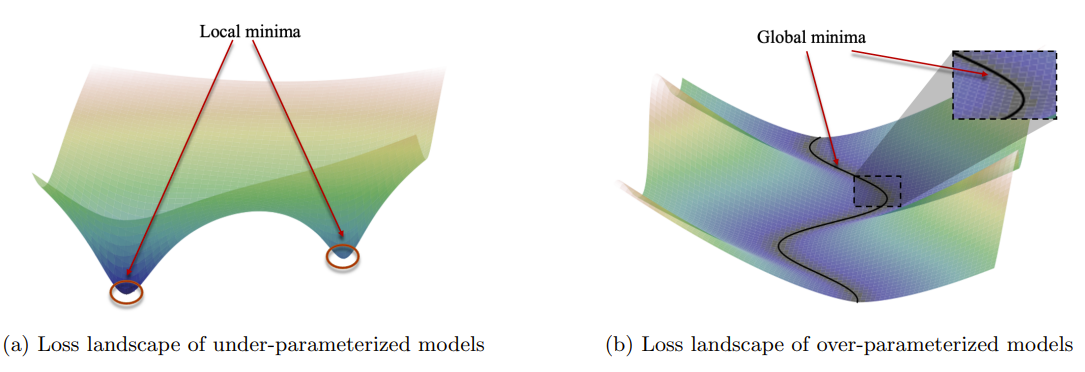
from https://arxiv.org/pdf/2003.00307.pdf
- Intuition of optimization in low dimensions often breaks down in high dimensions and with overparameterization
- Many classic examples where adding in more parameters makes optimization easier (e.g., more degrees of freedom to move)